Wie du vielleicht schon bemerkt hast – zumindest wenn du SQL Performance Explained gelesen hast – glaube ich nicht, dass Clustered-Indizes so nützlich sind, wie viele behaupten. Das kommt daher, dass die Wahl eines guten Clusterschlüssels (Clustering Keys) verdammt schwierig ist. In der Tat ist die Wahl eines guten – des „richtigen“ – Clusterschlüssels nahezu unmöglich, sobald die betroffene Tabelle mehr als ein oder zwei Indizes hat. Das Ergebnis ist, dass oft der Default Clusterschlüssel verwendet wird—also der Primärschlüssel. Leider ist das fast immer die falsche Wahl.
In diesem Artikel erkläre ich die Bestie namens Clustered-Index mit allen Nachteilen. Obwohl der Artikel SQL Server also Demo-Datenbank verwendet, trifft das Gesagte auch auf Oracle Index-organisierte Tabellen und MySQL mit InnoDB zu.
Wiederholung: Was ist ein Clustered-Index?
Die Idee hinter Clustered-Indizes ist es, den kompletten Inhalt einer Tabelle in der Datenstruktur eines B-Tree Indexes zu speichern. Wenn eine Tabelle einen Clustered-Index hat, bedeutet das, dass der Index die Tabelle ist. Wie jeder B-Tree Index hat auch ein Clustered-Index eine strenge Ordnung: die Zeilen sind entsprechend der Indexdefinition sortiert – bei einem Clustered-Indexes nennt man das den Clusterschlüssel (Clustering Key). Alternativ kann man eine Tabelle auch ohne besondere Ordnung in einem „Haufen“ (Heap) speichern. Clustered-Indizes haben den Vorteil, dass sie sehr schnelle Bereichs-Zugriffe ermöglichen. Das heißt, sie können Zeilen mit dem gleichen (oder ähnlichen) Clusterschlüssel sehr schnell liefern, weil sie physisch nebeneinander gespeichert sind – oft im selben Datenblock. Bei Clustered-Indizes muss man sich immer vor Auge halten, dass es keine separate Tabelle mehr gibt. Der Clustered-Index ist der primäre Tabellenspeicher—daher kann es auch nur einen pro Tabelle geben. Das ist die Definition von Clustered-Index – der Fokus liegt hierbei auf der Abgrenzung zu Heap-Tabellen.
Ein anderer Weg Clustered-Indizes zu begegnen ist über die Abgrenzung gegenüber Non-Clustered-Indizes. Schon alleine des Namens wegen ist das oft der logischere Gegensatz zu Clustered-Indizes. Aus diesem Blickwinkel ist der wichtigste Effekt, dass Zugriffe auf einen Clustered-Index immer als Index-Only-Scan erfolgen. Ein Non-Clustered-Index beinhaltet hingegen nicht alle Tabellenspalten, sodass zusätzliche Leseoperationen verursacht werden um, die restlichen Spalten wenn nötig aus dem primären Tabellenspeicher zu laden. Dafür hat jede Zeile in einem Non-Clustered-Index einen Verweis auf ebendiese Zeile im primären Tabellenspeicher. In anderen Worten geht ein Non-Clustered-Index grundsätzlich mit dem Auflösen einer zusätzlichen Indirektion einher. Grundsätzlich habe ich gesagt. Es ist nämlich recht einfach diesen Aufwand zu vermeiden, indem man alle benötigen Spalten in den Non-Clustered-Index aufnimmt. Dadurch kann die Datenbank diese Daten direkt aus dem Index entnehmen und das Auflösen der zusätzlichen Indirektion einfach auslassen. Auch Non-Clustered-Indizes können also für Index-Only-Scans genutzt werden und damit ebenso schnell wie Clustered-Indizes sein. Ist das nicht das, worauf es ankommt?
Beachte
Der Index-Only-Scan ist das wichtige Konzept – nicht der Clustered-Index.
Im weiteren Verlauf des Artikels werden wir sehen, dass es eine gewisse Dualität zwischen den Aspekten des Clustered-Indexes gibt: einerseits ist er ein Tabellenspeicher (alternativ zu Heap-Tabellen), andererseits ist er ein Index der „zufällig“ alle Tabellenspalten beinhaltet. Leider kann diese Tabelle-Index-Dualität genauso verwirrend sein wie die Welle-Teilchen-Dualität des Lichtes. Daher werde ich in diesem Artikel immer, wenn es nötig ist, darauf hinweisen, welcher Aspekt gerade zum Vorschein tritt.
Die Kosten einer zusätzlichen Indirektion
Wenn es um Performance geht, ist eine zusätzliche Indirektion keineswegs erstrebenswert, da das Auflösen Zeit beansprucht. An dieser Stelle ist es wichtig, dass die Kosten der zusätzlichen Indirektion maßgeblich vom gewählten Tabellenspeicher beeinflusst werden – also davon, ob man eine Heap-Tabelle oder einen Clustered-Index nutzt.
Die folgenden Abbildungen verdeutlichen dieses Phänomen. Sie zeigen den Ablauf eine Abfrage für alle SALES-Einträge von 2012-05-23. Die erste Abbildung zeigt dazu einen Non-Clustered-Index auf SALE_DATE und eine Heap-Tabelle als Tabellenspeicher (= eine Tabelle, die keinen Clustered-Index hat).
Der Ablauf beginnt links mit einer Index Seek Operation auf dem Non-Clustered-Index. Dieser Indexzugriff löst in weitere Folge zwei RID Lookups auf die Heap-Tabelle aus – einen für jede passende Zeile. Diese Operation entspricht dem Dereferenzieren der zusätzlichen Indirektion, um die restlichen Spalten aus dem primären Tabellenspeicher (Heap) zu laden. Bei Heap-Tabellen verwendet ein Non-Clustered-Index dafür die physische Speicheradresse (die RID) um auf die jeweilige Zeile in der Heap-Tabelle zu verweisen. Im schlimmsten Fall führt diese Dereferenzierung also zu einem zusätzlichen Lesezugriff pro Zeile (wenn man Forwarding vernachlässigt).
Betrachten wir als Nächstes dasselbe Szenario mit einem Clustered-Index. Genauer gesagt, wenn man weiterhin einen Non-Clusterd-Index auf SALE_DATE verwendet, es aber einen Clustered-Index auf SALE_ID gibt – also mit dem Primärschlüssel als Clusterschlüssel.
Beachte, dass sich die Definition des linken Indexes nicht geändert hat: Es ist nach wie vor ein Non-Clustered-Index auf SALE_DATE. Dennoch beeinflusst das bloße Vorhandensein des Clustered-Indexes die Art, wie der Non-Clustered-Index auf den primären Tabellenspeicher verweist – also auf den Clustered-Index! Im Gegensatz zu Heap-Tabellen sind Clustered-Indizes „lebende Kreaturen,“ die Zeilen nach Bedarf verschieben, um die Index-Reihenfolge und die Balance zu wahren. In weitere Folge können Non-Clustered-Indizes die physische Adresse nicht als Referenz verwenden – schließlich könnte sie sich jederzeit ändern. Stattdessen wird der Clusterschlüssel SALE_ID dafür genutzt. Das Laden der restlichen Spalten aus dem primären Tabellenspeicher (=Clustered-Index) zieht daher das durchwandern eines ganzen Indexbaumes nach sich. Im Gegensatz zu Heap-Tabellen ist das nicht bloß ein zusätzlicher Lesezugriff, sondern gleich mehrere – für jede Zeile!
Ich nenne diesen Effekt auch „Clustered-Index Penalty.“ Diese „Strafe“ trifft alle Non-Clustered-Indizes auf Tabellen, die einen Clustered-Index haben.
Beachte
Die Oracle-Datenbank speichert bei Index-organisierten Tabellen zusätzlich zum Clusterschlüssel auch einen Hinweis in den sekundären Indizes (=Non-Clustered-Indizes) ab, wo die Zeile zuletzt gespeichert war („guess ROWID“). Falls die Zeile tatsächlich dort gefunden wird, muss der B-Tree nicht durchwandert werden. Wenn die Zeile dort allerdings nicht mehr ist, wurde ein Lesezugriff umsonst durchgeführt.
Wie schlimm ist es?
Nun, da wir gesehen haben, dass Clustered-Indizes einen beachtlichen Mehraufwand beim Zugriff über Non-Clustered Indizes verursachen, fragst du dich bestimmt, wie schlimm es ist? Die theoretische Antwort haben wir bereits oben gesehen: anstatt eines Lesezugriffs pro Zeile beim RID Lookup braucht ein Key Lookup (Clustered) gleich mehrere. Durch meine Performance-Schulungen habe ich eins jedoch auf die harte Tour gelernt: Die Leute tendieren dazu diese Tatsache zu ignorieren, zu leugnen oder ganz schlicht und einfach nicht zu glauben. Daher folgt nun eine Demonstration.
Natürlich verwende ich dafür zwei grundsätzlich idente Tabellen, die sich nur durch die Form des Tabellenspeichers unterscheiden (Heap bzw. Clustered). Das folgende Listing zeigt das Muster, zum Erstellen dieser Tabellen. Die Teile in eckigen Klammern steuern, ob man eine Heap-Tabelle oder einen Clustered-Index als Tabellenspeicher verwendet.
CREATE TABLE sales[nc] (
sale_id NUMERIC NOT NULL,
employee_id NUMERIC NOT NULL,
eur_value NUMERIC(16,2) NOT NULL,
SALE_DATE DATE NOT NULL
CONSTRAINT salesnc_pk
PRIMARY KEY [nonclustered] (sale_id),
);
CREATE INDEX sales[nc]2 ON sales[nc] (sale_date);Für die Demo wurden diese Tabellen mit 10 Millionen Zeilen gefüllt.
Als Nächstes brauchen wir eine Abfrage, die uns erlaubt den Performance-Unterschied zu messen.
SELECT TOP 1 *
FROM salesnc
WHERE sale_date > '2012-05-23'
ORDER BY sale_dateDie Idee hinter dieser Abfrage ist es den Non-Clustered-Index zu nutzen (daher: Filterung und Sortierung auf SALE_DATE) um eine beliebige Anzahl an Zeilen (daher: TOP N) aus dem primären Tabellenspeicher zu holen (daher: select *, damit die Abfrage nicht als Index-Only-Scan ausgeführt wird).
Durch SET STATISTICS IO ON können wir messen, wie viele logische Leseoperationen diese Abfrage verursacht, wenn man sie gegen die Heap-Tabelle ausführt:
Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0,…Der wichtige Messwert ist: vier logical reads. Da die Abfrage zweimal ausgeführt wurde, gab es aufgrund des Caches keine physischen Lesezugriffe. Mit der Info, dass nur eine Zeile aus einer Heap-Tabelle geladen wurde, können wir bereits darauf schließen, dass der Baum des Non-Clustered-Indexes drei Ebenen hat. Mit einem weiteren Lesezugriff auf die Heap-Tabelle ergibt das insgesamt die vier Lesezugriffe, die oben angezeigt wurden.
Um diese These zu prüfen, selektieren wir zwei Zeilen:
SELECT TOP 2 *
FROM salesnc
WHERE sale_date > '2012-05-23'
ORDER BY sale_dateScan count 1, logical reads 5, physical reads 0, read-ahead reads 0,…Denke daran, dass diese Änderung die Suche im Non-Clustered-Index im Wesentlichen unberührt lässt – im wahrscheinlichen Fall, dass die zweite Zeile in derselben Indexseite gespeichert ist, benötigt die Suche nach wie vor drei Lesezugriffe. Daher sehen wir oben auch nur einen zusätzlichen Lesezugriff, um die zweite Zeile aus der Heap-Tabelle zu laden.
Nun wiederholen wir dieses Experiment mit der Tabelle, die einen Clustered-Index hat (bzw. ein Clustered-Index ist!).
SELECT TOP 1 *
FROM sales
WHERE sale_date > '2012-05-23'
ORDER BY sale_dateScan count 1, logical reads 8, physical reads 0, read-ahead reads 0,…Das Selektieren einer Zeile benötigt bereits acht Lesezugriffe – doppelt so viele wie zuvor. Wenn wir annehmen, dass der Non-Clustered-Index auch drei Ebenen hat, bedeutet das, dass die
KEY Lookup (Clustered)
Operation fünf Lesezugriffe pro Zeile anstößt. Prüfen wir das, indem wir eine zweite Zeile selektieren.
SELECT TOP 2 *
FROM sales
WHERE sale_date > '2012-05-23'
ORDER BY sale_dateScan count 1, logical reads 13, physical reads 0, read-ahead reads 0,…Wie befürchtet steigt die Zahl der Lesezugriffe damit um weitere fünf.
Um ein besseres Bild zu gewinnen, habe ich diese Tests in 1/2/5er-Schritten bis 100 durchgeführt:
| Rows Fetched | Logical Reads (Heap) | Logical Reads (Clustered) |
|---|---|---|
| 1 | 4 | 8 |
| 2 | 5 | 13 |
| 5 | 8 | 27 |
| 10 | 13 | 48 |
| 20 | 23 | 91 |
| 50 | 53 | 215 |
| 100 | 104 | 418 |
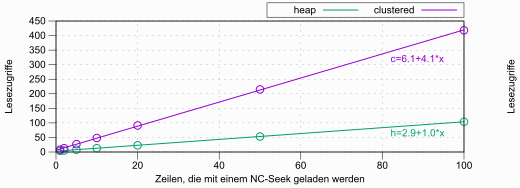
In der Graphik habe ich auch die linearen Funktionen eingepasst – danke, Gnuplot – damit man ablesen kann, wie sich die Steigung unterscheidet. Bei der Heap-Tabelle kommt die Gleichung den theoretischen Werten von oben sehr nahe (3 + 1 Zugriffe pro Zeile). Beim Clustered-Index sehen wir jedoch, dass anstatt der oben ermittelten fünf „nur“ vier Lesezugriffe pro Zeile anfallen.
Wen kümmern schon logische Lesezugriffe?
Die Anzahl der logischen Lesezugriffe ist ein nützlicher Maßstab, weil die Messung wiederholbare Ergebnisse liefert – unabhängig davon, welche Daten momentan im Cache sind oder welche anderen Aktivitäten gerade im System ablaufen. Das darf jedoch nicht darüber hinwegtäuschen, dass diese Messung noch immer eher theoretischer Natur ist. Viermal so viele Lesezugriffe heisst nicht automatisch, dass es auch viermal so lange dauert. In der Praxis ist ein guter Teil des Clustered-Indexes im Cache – zumindest die obersten Ebenen des B-Trees. Das reduziert der Effekt auf jeden Fall. Um das zu zeigen, habe ich einen weiteren Test durchgeführt und die Ausführungszeit gemessen, wenn die Abfrage komplett aus dem Cache bedient werden kann. Durch die gänzliche Vermeidung realer Festplattenzugriffe erhält man ebenfalls verhältnismäßig stabile Ergebnisse, die man untereinander vergleichen kann.
Den Test habe ich wieder in 1/2/5er-Schritten durchgeführt, musste jedoch mit 10,000 Zeilen beginnen, da die Timerauflösung bei kleineren Datenmengen nicht ausreichte. Bei mehr als 200,000 Zeilen stieg die Ausführungszeit eklatant an – vermutlich, weil die Abfrage nicht mehr aus dem Cache bedient werden konnte. Daher habe ich darüber hinaus keine weiteren Daten gesammelt.
| Zeilen Selektiert | Zeit (Heap) | Zeit (Clustered) |
|---|---|---|
| 10.000 | 31 | 78 |
| 20.000 | 47 | 130 |
| 50.000 | 109 | 297 |
| 100.000 | 203 | 624 |
| 200.000 | 390 | 1232 |
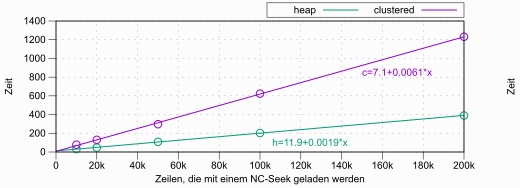
Laut diesem Test ist die „Clustered-Index-Penalty“ für den Non-Clustered-Index ungefähr dreimal so groß gegenüber bei einer Heap-Tabelle.
Ungeachtet dieser Messungen kann die „Clustered-Index-Penalty“ in einer Produktionsumgebung durch das reale Caching auch außerhalb des hier beobachteten Spektrums liegen.
Was war nochmals der Vorteil von Clustered-Indizes?
Der Vorteil von Clustered-Indizes ist, dass sie beim direkten Zugriff – nicht über einen Non-Clustered-Index – aufeinanderfolgende Zeilen sehr schnell liefern können. In anderen Worten sind sie schnell, wenn man den Clusterschlüssel verwendet, um mehrere Zeilen zu selektieren. Denk dabei daran, dass der Primärschlüssel per Default als Clusterschlüssel verwendet wird. In diesem Fall heißt das: Mehrere Zeilen über den Primärschlüssel selektieren – in einer Abfrage. Hmm. Mit einer Ist-Gleich-Bedingung kann man das natürlich nicht erreichen. Aber wie oft verwendet man schon andere Bedingungen wie > oder < mit einem Primärschlüssel? Manchmal, vielleicht, aber nicht so oft, dass es sich auszahlt, die ganze Tabellenstruktur dafür zu optimieren und sämtliche anderen Indizes mit der „Clustered-Index-Penalty“ zu bestrafen. Das ist meiner Meinung nach wirklich verrückt.
Zum Glück ist SQL Server sehr flexibel bei Clustered-Indizes. Im Gegensatz zu MySQL/InnoDB kann SQL Server beliebige Spalten als Clusterschlüssel verwenden – auch wenn sie nicht eindeutig sind (non-unique). Man kann also die Spalten, durch die die meisten Bereichszugriffe entstehen, als Clusterschlüssel verwenden. Bedenke dabei, dass auch Ist-Gleich-Bedingungen zu Bereichszugriffen führen können – jedoch nur auf non-unique Spalten. Vorsicht ist dennoch geboten: Verwendet man zahlreiche oder lange Spalten als Clusterschlüssel, bläht man damit alle Non-Clustered-Indizes auf, weil jeder davon den Clusterschlüssel als Referenz auf den primären Tabellenspeicher zu jeder Zeile mitspeichert. Darüber hinaus erweitert SQL Server den Clusterschlüssel automatisch, um ihn eindeutig (unique) zu machen, wenn man keine eindeutigen Spalten mit aufnimmt – auch das bläht alle Non-Clustered-Indizes auf. Obwohl dieses „aufblähen“ den Index-Baum der Non-Clustered-Indizes dank des logarithmischen Wachstums meistens nicht tiefer macht, kann es die Cache-Hit-Rate negativ beeinflussen. Daher habe ich oben auch erwähnt, dass die „Clustered-Index-Penalty“ auch außerhalb des gemessenen Bereiches liegen kann.
Selbst wenn man den Clusterschlüssel identifizieren kann, der den größten Vorteil für Bereichszugriffe bringt, besteht immer das Risiko, dass die „Clustered-Index-Penalty“ auf den Non-Clustered-Indizes diesen Vorteil zunichtemacht. Wie ich eingangs schon erwähnt habe, ist es verdammt schwierig einen guten Clusterschlüssel zu wählen, da es sehr komplexe Auswirkungen auf alle anderen Indizes hat. Daher bevorzuge ich, wenn möglich, Heap-Tabellen und verwende wenn nötig Index-Only-Scans. Aus diesem Blickwinkel ist ein Clustered-Index nichts weiter als eine zusätzliche Möglichkeit zur Platzoptimierung, wenn die „Clustered-Index-Penalty“ kein Thema ist – vor allem, wenn man nur einen Index für Bereichszugriffe benötigt.
Beachte
Manche Datenbanken unterstützten keine Heap-Tabellen – allen voran MySQL/MariaDB mit InnoDB und die Azure Datenbank.
Weiters gibt es Konfigurationen, in denen man nur den Primärschlüssel als Clusterschlüssel nutzen kann – das sind Oracle Index-organisierte Tabellen und wieder MySQL/MariaDB mit InnoDB.
Achtung: MySQL/MariaDB stehen auf beiden Listen: Sie bieten keine Alternative zu dem, was ich oben als „verrückt“ bezeichne. MyISAM ist keine Alternative.
Abschliessend: Wie viele Clustered-Indizes kann eine SQL Server Tabelle haben?
Abschliessend möchte ich noch kurz demonstrieren, warum es schlecht ist, den Clustered-Index als „Siver-Bullet“ zu betrachten und ihn in den Mittelpunkt sämtlicher Performance-Überlegungen zu stellen. Diese Demonstration ist ganz einfach. Nimm dir einfach einen Moment Zeit und denke über die folgende Frage nach:
Wie viele Clustered-Indizes kann eine SQL Server Tabelle haben?
Ich stelle diese Frage leidenschaftlich gerne in SQL Server Performance Schulungen. Sie zeigt, wie schlecht Clustered-Indizes verstanden werden.
Die spontane Antwort der Kursteilnehmer ist meistens „einen!“ Daraufhin frage ich dann, warum man keinen Zweiten haben kann. Typische Antwort: —Stille—. Nachdem du diesen Artikel gelesen hast, kennst du die Antwort natürlich: Ein Clustered-Index ist nicht nur ein Index, sondern auch der primäre Tabellenspeicher. Man kann ganz schlicht und einfach keinen zweiten primären Tabellenspeicher haben. Logisch, oder? Meine nächste Frage ist dann, ob jede SQL Server Tabelle einen Clustered-Index haben muss. Typische Antwort: —Stille— oder „nein“ in einem fragenden Ton. An diese Stelle dürften die Teilnehmer durchschauen, dass ich Fangfragen stelle. Wie auch immer, du weißt jetzt, dass SQL Server auch ohne Clustered-Index auskommt und die Tabelle dann einfach in einem Haufen (Heap) speichert.
Definitionsgemäß ist die Antwort auf die Frage daher: „nicht mehr als einen.“
Und jetzt wollen wir aufhören, im Clustered-Index eine Wunderwaffe zu sehen und stattdessen den Index-Only-Scan in den Mittelpunkt rücken. Dafür formuliere ich die Frage neu:
Wie viele Indizes kann man auf einer SQL Server Tabelle haben, die so schnell abgefragt werden können wie ein Clustered-Index?
Der Unterschied gegenüber der ursprünglichen Formulierung von oben ist, dass der Fokus nicht mehr auf dem Clustered-Index als solches liegt, sondern auf dem positiven Effekt, den man von einem Clustered-Index erwartet. Schließlich verwendet man einen Clustered-Index nicht um seiner selbst willen, sondern um damit die Performance zu verbessern. Also wollen wir uns darauf konzentrieren.
Die Geschwindigkeit eines Clustered-Indexes kommt dadurch zustande, dass jeder (direkte) Zugriff als Index-Only-Scan ausgeführt werden kann. Daher ist die Frage im Wesentlichen: „Wie viele Indizes können einen Index-Only-Scan unterstützen?“ Antwort: So viele, wie du willst. Dazu muss man einfach nur alle referenzierten Spalten einer Abfrage in den entsprechenden Non-Clustered-Index aufnehmen und *ZACK* ist die Abfrage so schnell, als wäre es ein Clustered-Index. Genau dafür gibt es bei SQL Server das Schlüsselwort INCLUDE bei der CREATE INDEX Anweisung.
Wenn man sich auf den Index-Only-Scan anstatt auf den Clustered-Index konzentriert, bringt das einige Vorteile:
Man ist nicht auf einen Index eingeschränkt. Jeder Index kann so schnell sein, wie ein Clustered-Index.
Das Erweitern eines Indexes für einen Index-Only-Scan (
INCLUDE-Spalten) beeinflusst nur diesen einen Index. Es gibt keine „Penalty“ für alle anderen Indizes.Man muss nicht unbedingt alle Spalten der Tabelle in den Non-Clustered-Index aufnehmen, um ihn für einen Index-Only-Scan zu nutzen. Es genügt die Spalten aufzunehmen, auf die die Abfrage zugreift, die optimiert werden soll. Der Index bleibt kleiner und kann dadurch sogar noch schneller als ein Clustered-Index werden.
Und das Beste ist: Index-Only-Scans und Clustered-Indizes schliessen einander nicht aus. Der Index-Only-Scan funktioniert unabhängig vom verwendeten Tabellenspeicher. Man kann auch Non-Clustered-Indizes für einen Index-Only-Scan nutzen, wenn es auf der Tabelle einen Clustered-Index gibt.
Wegen der „Clustered-Index-Penalty“ ist das Konzept des Index-Only Scans sogar noch wichtiger, wenn man einen Clustered-Index hat. Wenn es überhaupt so etwas wie eine Wunderwaffe zur Performance-Optimierung gibt, ist es der Index-Only-Scan – und nicht der Clustered-Index.
Wenn dir dieser Artikel gefällt, wirst du SQL Performance Explained lieben.

