Un hardware más grande no significa siempre que sea más rápido, pero generalmente puede manejar más carga. Un hardware más grande es más como una autopista más amplia y no un coche más rápido; no se puede conducir más rápido (¡no se lo permiten!) solamente porque existan más carriles. Esa es la razón por la cual más hardware no mejorará automáticamente sentencias SQL lentas.
Ya no estamos en los años 1990. En aquella época el poder de los servidores de un solo núcleo fue aumentando rápidamente. La mayoría de los problemas de tiempos de respuesta desaparecían con el nuevo hardware solamente porque se incrementó la CPU. Era como si cada año los nuevos modelos de coches fuesen dos veces más rápido que los modelos antiguos. Sin embargo, el poder de un solo núcleo CPU se detuvo durante los primeros años del siglo XXI. Prácticamente ya no existían mejoras en esta dimensión. Para seguir produciendo CPU con más rendimiento, los fabricantes tuvieron que impulsar la tecnología multi-núcleo. Sin embargo, aunque esta tecnología permite múltiples trabajos en ejecución simultáneos, el rendimiento no mejorará si existe solamente un trabajo. El rendimiento no tiene más de una dimensión.
La escalabilidad horizontal (agregando más servidores) tiene las mismas limitaciones. Aunque más servidores pueden procesar más solicitudes, para una sentencia en particular no mejora el tiempo de respuesta. Para hacer la búsqueda más rápida se debe tener una búsqueda del árbol más eficiente, incluso en sistemas no relacionales como CouchDB y MongoDB.
Importante
Indexar correctamente es la mejor manera de reducir los tiempos de respuesta; tanto en las bases de datos SQL relacionales como los sistemas no relacionales.
Indexar correctamente pretende explotar la escalabilidad logarítmica del índice B-tree. Desafortunadamente, la indexación suele realizar de forma descuidada. La gráfica del “Impacto del volumen de datos sobre el rendimiento” muestra el efecto evidente del descuido en la indexación.
Figura 3.5 Tiempo de respuesta por volumen de datos
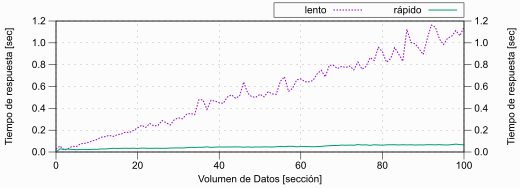
Muchos de los llamados sistemas NoSQL aún aseguran resolver todos los problemas de rendimiento con la escalabilidad horizontal. Sin embargo, la escalabilidad es limitada sobre todo para las operaciones de escritura, y donde además se usa la consistencia eventual como modelo de consistencia. Las bases de datos SQL usan un modelo de consistencia estricto que potencialmente frena las operaciones de escritura (para hacerlas consistentes), pero eso no implica necesariamente mal rendimiento. Se aprenderá más acerca de eso en la sección titulada “Consistencia eventual y teorema de CAP”.
Normalmente, añadir más hardware no mejora los tiempos de respuesta. De hecho, podría hacer el sistema más lento porque la complejidad podría provocar que se añadan más latencias. Las latencias de redes no son el problema si la aplicación y la base de datos se ejecutan sobre el mismo servidor, pero esta configuración es bastante inusual en ambientes de producción en los que la base de datos y la aplicación generalmente se instalan en hardware dedicado. Las políticas de seguridad podrían requerir un cortafuegos entre el servidor de aplicación y la base de datos y, con frecuencia, eso multiplica por dos las latencias de red. Cuanto más compleja es la infraestructura, más latencias se acumulan y más lenta llega a ser la respuesta. Este efecto lleva muchas veces a la observación según la cual el hardware costoso de producción es más lento que el equipo de escritorio barato usado para el desarrollo.
Otra latencia muy importante es el tiempo de búsqueda en el disco. Los discos duros giratorios (en inglés HDD) necesitan bastante tiempo para colocar la parte mecánica hasta que el dato solicitado pueda ser leído, típicamente unos milisegundos. Esa latencia ocurre cuatro veces cuando se recorre un nivel de un B-tree; en total, unas docenas de mili-segundos. Aunque es la mitad de la eternidad para los servidores, sigue estando muy por debajo del umbral de percepción humana...mientras se haga solamente una vez. Sin embargo, es muy fácil desencadenar centenares o miles de tiempos de búsqueda en el disco con una sola sentencia SQL, en particular cuando se juntan múltiples tablas con una operación de unión (“Join”). Aunque la “caché” reduce drásticamente el problema y las nuevas tecnologías, como SSD, reducen el tiempo de búsqueda significativamente, las uniones son, por lo general, sospechosas de ser responsables del mal rendimiento. El siguiente capítulo explicará, por lo tanto, cómo usar índices eficientes para las uniones de tablas.
Si te gusta mi manera de explicar, te encantará mi libro.
Hechos
El rendimiento tiene dos dimensiones: tiempo de respuesta y capacidad.
Más hardware no mejora el tiempo de respuesta de una sentencia.
Indexar correctamente es la forma óptima para mejorar el tiempo de respuesta de una sentencia.
Ver también
NoSQL, consistencia eventual y Teorema de Brewer o CAP en Wikipedia
Artículo: “Las razones correctas para elegir NoSQL.”

